Delta

Delta 简介
Delta 隐私计算网络由 Delta Node 和区块链节点组成。Delta Node 通过 Chain Connector 抽象层连接到区块链节点,在区块链上注册身份,获取待执行的计算任务,并上报计算过程和计算结果数据。
Delta Node 负责计算任务的整个生命周期管理:包括任务注册、多节点间任务协调、任务本地执行、结果上报、结果聚合等整个任务执行流程,在整个生命周期中保证本地数据的隐私安全;对外提供 API,供 IDE 等其他系统接入。
Delta Node 按功能分为 Server 和 Client 两部分:
- Server 端是任务的发起方;
- 数据需求方编写编写计算任务代码,通过 Server 端的 API 注册到区块链。
- Client 端是计算任务的实际执行环境;
- Client 端监测链上的任务,从 Server 端获取计算任务代码,在本地的安全执行环境中通过 Data Connector 获取数据并执行计算;
- Data Connector 支持文件、关系型数据库、HDFS 等数据源,后两者未实现。
- Client 端上报本节点的计算结果片段,由 Server 端进行最终的聚合,得到计算结果,最终计算结果仅有发起任务的 Server 端可以获取到;
- Client 端监测链上的任务,从 Server 端获取计算任务代码,在本地的安全执行环境中通过 Data Connector 获取数据并执行计算;
Delta Node 之间组成一个网络,用于计算任务的内容下发、结果上报以及安全多方计算、PSI 等隐私计算技术涉及到的多方秘密共享。
Delta 的隐私计算任务(Delta Task)用 Python 编写,提供了 开发框架 ,封装了隐私计算,开发者只需编写计算逻辑;支持 PyTorch 编写的机器学习任务和 Pandas 编写的数据分析任务。
Delta 将任务分类为横向联邦学习、纵向联邦学习和联邦统计。
Delta 中区块链的作用:
- 点对点网络构建;
- 计算任务发布和计算任务协调;
- 数据和计算的可信性保障;
官方了提供 Delta Chain 节点 和合约。
- Delta Chain 基于 Substrate,EVM 兼容;Substrate 是主打多链兼容的区块链开发框架,属于 Polkadot 生态,用 Rust 编写;
- Delta 合约使用 Solidity 编写;
- Delta 提供 区块链浏览器 ;
对接一个新的区块链系统的连接需要做以下工作:
- 实现 Delta 智能合约;
- 如果目标区块链系统使用 EVM 做为智能合约层,可以直接使用 Delta 的
Solidity 合约
,其它的区块链系统则需要参照 Delta 的智能合约(
/contracts目录),实现一套功能和接口完全一样的合约;- 合约主要包含横向联邦学习、逻辑回归和 ZKP PLONK scheme 的实现。
- 如果目标区块链系统使用 EVM 做为智能合约层,可以直接使用 Delta 的
Solidity 合约
,其它的区块链系统则需要参照 Delta 的智能合约(
- 在
delta-chain-connector
中实现调用区块链的
所有方法
;
- 方法数量 50+,用 TypeScript 编写;目前有
coordinator和ethereum两种实现; - Chain Connector 使用以太坊 pub/sub 接口来订阅以太坊事件,因此需要目标区块链系统支持 pub/sub 事件订阅,不兼容的区块链需要实现对应的支持,比如用 json-rpc 替代掉 pub/sub 方法。
- 方法数量 50+,用 TypeScript 编写;目前有
- 如果要使用数据和计算的可信性保障,区块链需要支持 zk-SNARKs 底层需要的密码学操作 EC Pairing;
Chain Connector 支持配置加密用用于密钥托管。
区块链节点非必须,Chain Connector 设置为 coordinator 模式时 Chain Connector 成为中心节点,连接多个 Delta Node 直接完成组网和计算任务协调的功能。
项目提供 Deltaboard 用于 Delta Node 的可视化管理,内嵌 JupyterLab IDE,支持在线任务编写、调试、运行;支持账号和权限配置,可多人同时提交计算任务。
http://192.168.11.146:8090/dashboard/playground
Delta 架构图:

逻辑回归中 ZKP:
Delta 架构
系统参与者分为 3 种角色:
- 数据持有者
- 本地搭建 Delta 节点来接入隐私计算网络,Delta 节点可以访问到本地的原始数据。
- Delta 节点从网络中接收计算任务,本地完成计算后将结果发回网络。
- 数据需求方
- 使用 Delta Python 框架编写计算任务;计算任务分为统计计算和机器学习模型训练两类。
- 通过 Delta 节点提交计算任务到隐私计算网络,获取计算结果。
- 网络搭建者
- 攒局;搭建、维护隐私计算网络。
Delta 隐私计算网络是一个点对点的对等网络,每个节点由区块链节点和 Delta Node 计算节点组成,两者通过 Chain Connector 连接。
- 隐私计算网络首先由区块链节点完成 P2P 组网,Delta Node 通过 Chain Connector 抽象层连接到区块链节点,在区块链上注册身份,获取待执行的计算任务,并上报计算过程和计算结果数据。
- 将 Chain Connector 设置为
coordinator模式,在此模式下的 Chain Connector 无需区块链,可以做为网络中心节点,连接多个 Delta Node 直接完成组网和计算任务协调的功能。
- 将 Chain Connector 设置为
- Delta Node 之间也会形成一个网络,用于计算任务的内容下发、结果上报,以及安全多方计算、PSI 等隐私计算技术涉及到的多方秘密共享。
Delta Node
Delta Node 是整个隐私计算网络的核心,负责计算任务的整个生命周期管理,包括任务注册、多节点间任务协调、任务本地执行、结果上报、结果聚合等整个任务执行流程,在整个生命周期中保证本地数据的隐私安全,同时对外提供 API,供 IDE 等其他系统接入。
Delta Node 提供 API 供外部调用,完成任务注册、任务状态查询、计算结果下载等任务相关的功能,以及任务列表查询、节点状态查询、节点配置等节点管理的功能。
Delta Node 的核心是完成 Delta Task 的注册、全网分发和计算,按照功能可以分为 Server 和 Client 两部分。
- Server 端是任务的发起方。
- 数据需求方编写 Delta Task,通过 Delta Node 的 Server 端 API 提交到系统中,由 Server 端注册到区块链上开始执行。执行过程中其他节点的 Client 端会从 Server 端获取 Delta Task 代码,并上报本节点的计算结果片段,由 Server 端进行最终的聚合,得到计算结果。
- 出于安全和隐私的考虑,最终计算结果仅有发起任务的 Server 端可以获取到,不会在链上公开。
- 在需要多轮计算的任务中,Server 端会多次在链上发起计算请求,并综合多轮的计算得到最终结果。
- 数据需求方编写 Delta Task,通过 Delta Node 的 Server 端 API 提交到系统中,由 Server 端注册到区块链上开始执行。执行过程中其他节点的 Client 端会从 Server 端获取 Delta Task 代码,并上报本节点的计算结果片段,由 Server 端进行最终的聚合,得到计算结果。
- Client 端是计算任务的实际执行环境。
- Client 端监测链上的任务,获取到任务后,从发起方 Delta Node 的 Server 端获取执行代码(Delta Task),在本地的安全执行环境中通过 Data Connector 获取数据并执行计算。
- 在需要 MPC 时,Client 端会和其他 Delta Node 节点的 Client 端进行通信并进行一些加密数据的交换(此交换不会泄露原始数据)。
- 在横向联邦计算的场景中,计算结果会经过安全聚合加密,只有在任务发起的 Server 端拿到全部的加密结果片段后,进行累加,才能得到最终的平均数据,单个 Client 端的计算结果,不会有任何形式的暴露。
- Client 端监测链上的任务,获取到任务后,从发起方 Delta Node 的 Server 端获取执行代码(Delta Task),在本地的安全执行环境中通过 Data Connector 获取数据并执行计算。
Data Connector 是 Delta Node 的数据连接层,负责连接 Delta Node 和数据提供方的隐私数据,它包含一个对数据进行标准化描述的协议,Delta Task 中可以直接使用协议 SDK 来引用数据。Data Connector 支持连接多个不同的数据源,包括文件、关系型数据库、HDFS 等,并支持对数据源的数据进行自动校验和清洗。Delta Node 接收到计算任务后,判断自身的数据是否满足计算条件并上报给任务发起方,任务发起方根据各个节点的数据持有情况来决定采用哪种隐私计算策略。
Delta Node 的安全执行环境对于数据安全的保障分为以下几个方面:
- 隐私计算的算法保证:通过 MPC、横向和纵向联邦学习以及差分隐私,保证原始数据不对外泄露,以及单个节点的统计数据也不会对外泄露。Delta Task 的计算结果,只能拿到多个节点综合起来的统计数据,无法获取单个节点的统计数据。
- 对 Delta Task 代码的安全性检查:包括静态代码扫描以及动态影响范围检查两种方式,防止 Delta Task 中嵌入除了数据计算以外的恶意代码,造成数据泄露。
- 对 Python 执行环境的安全隔离,包括运行环境隔离和网络环境隔离等。
Delta Task
Delta 隐私计算框架的设计思想是对隐私计算进行封装隔离,让开发者无需了解隐私计算,只需要在 Delta Task 框架下编写计算逻辑。
Delta Task 用 Python 编写,开发者需要先引入 Delta Task 框架,实例化一个 Delta Task,并在 Delta Task 中完成数据预处理、训练模型的定义,然后将 Delta Task 发送到 Delta Node 进行执行。
- Delta supports running machine learning tasks written in PyTorch, and data analytics tasks written in Pandas.
Delta Node 接收到 Task 后,在全网完成任务的分发,并根据任务定义,以及其他节点上报的数据情况,决定隐私计算的类型,将任务分类为横向联邦学习、纵向联邦学习和联邦统计中的一种,按照对应的隐私计算算法完成任务拆分、多节点协调和计算结果汇总,最终完成计算并得到计算结果。
区块链
Delta 中区块链的作用:
- 点对点网络构建:网络节点发现、节点数字身份注册;
- 计算任务发布和计算任务协调:通过智能合约保证网络中关于计算任务的发布、运行、上报的规则能够被统一执行;
- 数据和计算的可信性保障:日常更新数据的链上零知识存证,以及计算任务执行过程的零知识证明上链和校验。
Delta 的区块链可以用 Delta Chain 搭建,也可使用任意其他区块链系统(比如 Ethereum),只需要部署 Delta 智能合约。
- 如果要使用数据和计算的可信性保障,Delta 中的区块链要支持 zk-SNARKs 底层需要的密码学操作 EC Pairing。
- Delta Chain 基于 Substrate,EVM 兼容; Substrate 是主打多链兼容的区块链开发框架,Rust。
Delta 抽象出了 Chain Connector 组件,用于管理 Delta Node 和区块链节点之间的连接。在 Chain Connector 中可以方便地切换不同的区块链系统,也支持配置一个额外的离线签名机用于密钥托管,实现密钥的离线保存和使用。
Delta 合约使用 Solidity 编写;Chain Connector 中实现了以太坊 API 的调用,理论上可以在所有兼容以太坊的区块链上运行,但是由于 Chain Connector 目前使用了以太坊的 pub/sub 接口来订阅以太坊事件,因此需要目标区块链系统支持 pub/sub 事件订阅。如果需要在不兼容的以太坊区块链上运行,需要开发者自己在 Chain Connector 中实现对应的支持,比如使用 json-rpc 替代掉 pub/sub 方法,这样就可以运行在没有 pub/sub 接口的区块链上。
对接一个新的区块链系统的连接需要做 2 块工作:
- 实现 Delta 智能合约;
- 如果目标区块链系统使用了 EVM 做为智能合约层,可以直接使用 Delta 的
Solidity 合约
,其它的区块链系统则需要参照 Delta 的智能合约(
/contracts目录),实现一套功能和接口完全一样的合约。- horizontal federated learning contract, horizontal logistic regression contract.
- 如果目标区块链系统使用了 EVM 做为智能合约层,可以直接使用 Delta 的
Solidity 合约
,其它的区块链系统则需要参照 Delta 的智能合约(
- 在
delta-chain-connector
中实现调用区块链的
所有方法
;
- 方法数量 50+,TypeScript;目前有
coordinator和ethereum两种实现;
- 方法数量 50+,TypeScript;目前有
Zero-Knowledge Proof
利用隐私计算,原先交易原始数据的模式变为交易计算结果的模式。
- Instead of paying for the original data, the buyer now sends the computation steps to several data holders, who perform the computation on their own data and get partial results. Privacy-Preserving Computation is used to sum up all the partial results to get the final result, in a way that no partial result of a single data holder will be revealed to others.
这种模式需要解决计算过程可信和原始数据可信两个问题:
- 计算过程可信
- 购买方给出计算步骤,同时给出一组零知识证明的“生成方法”和“验证方法”,这组方法和计算步骤相关,计算步骤不同,生成方法和验证方法也不同。
- 数据拥有者交付计算结果,同时用购买方提供的生成方法计算 Proof,一并发给购买方。
- 零知识证明保证了如果 Proof 通过验证,则计算结果一定是按照对应的计算步骤的要求算出来的。
- 原始数据可信
- 对于原始数据,技术上显然无法区分是真实的还是伪造的,也就无从验证,但通过零知识证明可以实现原始数据的溯源:
- 通过对零知识证明的设计,让 Proof 中包含原始数据的哈希值,这样就证明了计算结果是按照要求的计算步骤对哈希值对应的原始数据计算得到的。
- 必要时,购买方可以做抽样检验,要求数据持有者提供一部分原始数据,由购买方手工检查这些数据的质量。
- 对于原始数据,技术上显然无法区分是真实的还是伪造的,也就无从验证,但通过零知识证明可以实现原始数据的溯源:
示例:对逻辑回归计算任务的校验
The original data is distributed across multiple data holders horizontally. The PPC method used to do the training is Federated Learning.
The Logistical Regression (LR) training process is divided into several iterations.
The buyer starts the iteration by sending the initial model parameters to all the data holders.
Within each iteration:
- The data holder computes a gradient incremental on the model parameters given as the input and send the gradient incremental back.
- The plain text gradient is masked using secure aggregation algorithm before sending out.
- 单节点梯度值某种程度上也暴露了节点上数据的隐私。这里使用了横向联邦学习的安全聚合方法,每个计算节点给自己的梯度值加上一个掩码,再发送出来。安全聚合方法保证了所有计算节点的掩码后梯度值求和,可以得到准确的全局梯度值,但是无法获取到任何一个掩码前的单节点梯度值。
- After getting the global gradient, the buyer applies it to the model parameters, checks if the model is converged, and decides whether to start another iteration or not.
- The buyer can only get the global gradient by summing up all the masked gradient from all the data holders. The gradient of a single data holder is never exposed to the outside world.
- The incremental is applied to the model parameters, and those parameters are used as the input for the next iteration.
- When the incremental is zero, the model is converged, and the training is completed.
Each iteration starting from the private data and the initial model parameters and ends with the masked gradient. The mask is generated using asymmetric cryptography, which is by design of the Federated Learning. Including the mask generation process in the ZKP is already a mission too complex to finish and will make the ZKP generation too slow to be practical.
由于逻辑回归任务是一轮一轮执行的,最直接的验证流程设计,就是每一轮计算都由计算节点生成一个零知识证明,提交给区块链,证明自己按照要求完成了计算,也就是"计算过程验证"。每一轮计算节点的输出是一个经过掩码的梯度值,如果对这个梯度值生成零知识证明,就需要把安全聚合的整个计算过程也嵌入进去,会导致零知识证明极其复杂,生成成本也很高,速度很慢。
The buyer cares about is to get a converged model on the data he requires. If the model is converged, and the data is used, he is satisfied. No other information such as the number of iterations is needed.
To prove to the buyer that the parameters he received is converged, the data holder must generate a ZKP for the computation of one iteration, where the input is the converged model parameters, and the output is the gradient. Since this is done for only one iteration, exposing the gradient to the public won’t cause any privacy issues. We can safely ignore the masking process and reveal the gradient in the ZKP so that the Blockchain could sum up the gradient from all the data holders to check whether it is converged or not.
- This greatly reduces the amount of work required to generate the ZKP. Only one ZKP is required for a task instead of one ZKP for each iteration.
- The PPC steps are removed from the ZKP generation.
By calculating the hash of the original data in the computation steps, and including the hashing process in the ZKP, revealing the hash value as the public output, the ZKP has the ability to prove that the result is from the data with certain hash values.
The Blockchain doesn’t have the final converged model parameters. Those parameters are not visible to the Blockchain, nor are they revealed in the ZKP.
- How could the Blockchain be sure that the buyer actually gets the computation result he paid for?
- What if the buyer claims he does not get the result when he actually got it?
把零知识证明抽象成一组输入和输出:公开输入、秘密输入、公开输出。输入和输出和计算步骤对应。公开输入和公开输出能够从 Proof 数据中提取出来,对外部可见,秘密输入无法提取。
对于最后一轮的执行流程,得到的梯度值已满足模型模型收敛的要求,也就是说这一轮任务发起方给出的模型参数就是最终模型收敛的参数。
在零知识证明的秘密输入中加入模型参数,然后在公开输出中输出模型参数的哈希。轮次启动时,要求任务发起者将模型参数的哈希值上链。当模型收敛时,假设模型参数的哈希值是 A,A 实际上已经由任务发起者上链,任务发起者可以生成哈希值 A,说明它已经拥有哈希值 A 对应的模型参数。
Another way for the data holder to cheat is to reuse the ZKP of a task to pass the verification of another task. Technically the ZKP generation & verification methods are different for different computation tasks. When the buyer submits the task to the Blockchain, he should also submit the corresponding ZKP verification method to the Blockchain so that the Blockchain could use the correct verification method to check the ZKP.
- The data holder however, before executing the task, should also check the correctness of the verification method on-chain in case that the buyer submits an invalid verification method that he could never pass.
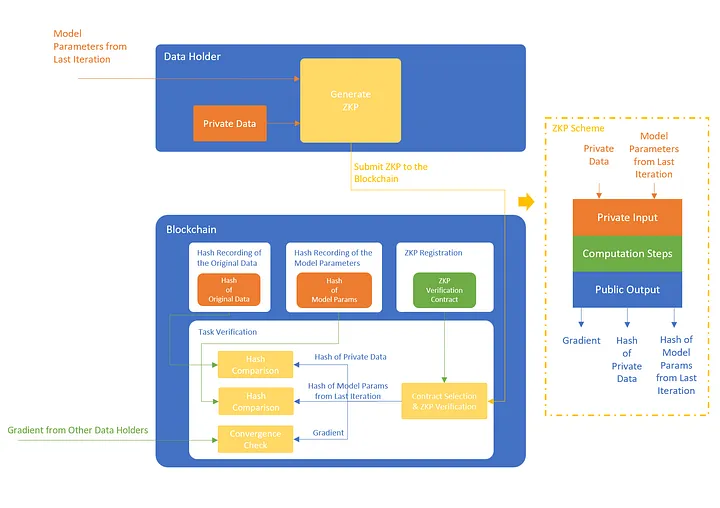
Workflow:
- The buyer starts the task, selects the right verification contract to use, saves the selection in the task config and submits the task config to the Blockchain.
- The iteration begins. For each iteration, the buyer calculates the hash of the initial model parameters and submits the hash to the Blockchain. After receiving the hash, the Blockchain notifies the data holders to start the iteration.
- The data holder fetches the hash from the Blockchain, retrieves the initial model parameters from the buyer, hashes it and compares the value with the value from the Blockchain. If the values are different, the data holder won’t start the calculation since he knows that he will not be able to pass the ZKP verification on-chain.
- The data holder then performs the training using the local private data, whose hash values have already been submitted to the Blockchain before. If the hash values are not on-chain, the verification later won’t pass.
- After the training, the data holder sends the masked gradient to the buyer and finishes the iteration.
- After receiving ZKP from the data holder, the Blockchain selects the verification contract that is specified in the task config, uses the contract to verify the correctness of the ZKP.
- If the ZKP passes the verification, the Blockchain further extracts the public outputs from the ZKP. And checks the correctness of the outputs:
- The hash of the private data is the same as the hash recorded on-chain.
- The hash of the model params of the last iteration is the same as the hash recorded on-chain.
- The gradient, summed up with the gradients from other data holders is below a preset threshold.
- If the buyer is malicious, he could also stop here, refuse to participate in any future steps since he has got the model already. In this case the verification process could as well be started by the data holders. As long as the verification passes, the data holders could get paid by the Blockchain using the money (tokens) prepaid by the buyer on-chain.
- If the ZKP passes the verification, the Blockchain further extracts the public outputs from the ZKP. And checks the correctness of the outputs:

There are still some problems left though.
- When the model is not converged after the training, if the data holder cannot prove that he did spend computing power on the training, could he still get paid?
- If one of the data holders fails to submit the ZKP, could others get paid?
- ZKP generation is still slow even after all these optimizations. If the dataset is large, we can hardly say that the above implementation is practical.
References

