Go 并发编程:协程和通道

Contents
Go 支持两种并发模式:
- 通过通道和协程实现 communicating sequential processes (CSP) 并发模型;
- CSP 并发模型中,值在独立的协程(activities)间之间传递,但大体上值还是限定在某一个通道中。
- 传统的共享内存模型。
TL;DR
泄漏的协程不会被自动回收,因此要确保结束掉(return)不会再用到的协程。
main函数返回时,所有协程会马上(abruptly)终止,但长期运行的后台服务显然不能接受协程泄漏。
通道使用完毕后,若不是要用广播机制,可以不主动去关闭,Go 的垃圾回收器若判断通道处于不可及(unreachable)的状态,就会自动将通道的资源回收,无论通道是否已关闭。
Go 的垃圾回收器会回收未使用的内存,但它不会去释放不在使用中的操作系统资源,如打开的文件和网络连接,这些资源必须显式地去关闭。
通道是引用类型,作为函数参数传递时,实际上是拷贝了引用,函数调用者和被调用的函数的通道变量都指向同一个数据结构。
两个相同类型的通道可以用 == 比较,若它们是对同一个数据结构的引用,则比较结果为 true;通道也可以和 nil 比较。
无缓冲通道的容量是 0。
对关闭通道进行接收操作可以取到已发送至该通道的值;通道内的值读完后继续进行接收操作,接收操作会立刻得到执行,取到的是通道元素类型的零值。
通道的接收操作会返回两个值:接收到的通道元素和一个布尔值。成功接收时布尔值为 true;接收的通道已关闭且通道里的值已接收完毕,布尔值为 false。由于这种用法十分常见,Go 也支持用 range 遍历通道实现同样的效果。
对关闭的通道进行发送操作会 panic。
关闭已经关闭的通道会 panic;关闭 nil 通道会 panic。
select 在通信发生前保持阻塞,通信发生时该通信对应的语句块被执行,其它的通信则没有机会再发生;没有 case 的 select 语句 select{} 永远保持阻塞。
若多个 case 都满足,select 会随机选择一个,保证每个通道被选中的概率相等。
select 语句可以有一个 default,指定没有其它通信可以进行时使用的逻辑,可以用来实现非阻塞通信。
select {} 在一个 case 执行完后才会解除阻塞,不是 case 里读通道操作成功就会解除阻塞。
https://go.dev/play/p/DVZaWQl8Sz-
对 nil 通道的发送和接收操作都会永远阻塞,在 select 语句中可以利用 nil 通道来启停某些功能,如处理超时、取消操作。
协程
进程(process)是应用程序的启动实例,每个进程都有独立的内存空间,不同进程通过进程间的通信方式来通信。
线程(thread)从属于进程,每个进程至少包含一个线程,线程是 CPU 调度的基本单位,多个线程之间可以共享进程的资源并通过共享内存等线程间的通信方式来通信。
协程(coroutine)可以认为是一种轻量级线程,它们之间存在量的差别,没有质的区别。与线程相比,协程不受操作系统调度,协程调度器由用户应用程序提供,协程调度器按照调度策略把协程调度到线程中运行。
Go 中每个并发执行的活动称为协程(goroutine);Go 的协程调度器由 runtime 包提供。
程序启动时,唯一的协程就是调用 main 函数的主协程。
Go 在语言层面即支持协程,新协程通过 go 语句创建,函数或方法的调用前加上 go 就能创建新协程并使其在新协程中执行,go 语句本身马上就执行完成。
func main() {
go spinner(100 * time.Millisecond)
const n = 45
fibN := fib(n)
fmt.Printf("\rFibonacci(%d) = %d\n", n, fibN)
}
func spinner(delay time.Duration) { // textual spinner
for {
for _, r := range `-\|/` {
fmt.Printf("\r%c", r)
time.Sleep(delay)
}
}
}
func fib(x int) int {
if x < 2 {
return x
}
return fib(x-1) + fib(x-2)
}
当 main 函数返回时,所有协程马上(abruptly)终止,程序退出。
除了 main 函数返回或是终止程序以外,一个协程无法(no programmatic way)终止其它协程,但一个协程可以与其它协程通信并将自己终止(通过 return 返回)。
协程示例
顺序时钟服务(一次只能处理一个连接):
func main() {
listener, err := net.Listen("tcp", "localhost:8000")
if err != nil {
log.Fatal(err)
}
for {
// Accept 在收到和 listener 建立的连接之前保持阻塞;收到连接后解除阻塞,并返回该连接
conn, err := listener.Accept()
if err != nil {
log.Print(err) // e.g., connection aborted
continue
}
handleConn(conn)
// go handleConn(conn) // 调用时加上 go 就变成并发时钟服务
}
}
func handleConn(c net.Conn) {
defer c.Close()
// 循环在写入失败时(如客户端断开连接)终止,handleConn 返回,Accept 才可以继续下一轮循环,等待新的连接进来
for {
_, err := io.WriteString(c, time.Now().Format("15:04:05\n")) // net.Conn 实现了 io.Writer,可以直接向其写入
if err != nil {
return // e.g., client disconnected
}
time.Sleep(1 * time.Second)
}
}
time.Time.Format 用于格式化时间日期,它的参数是一个时间的格式模板,给出格式化参考时间 Mon Jan 2 03:04:05PM 2006 UTC-0700(8 个组分)的说明,8 个组分中的任意多个组分可以以任意的顺序和多种格式被用作参数。time 包还定义了许多标准的时间格式,如 time.RFC1123。
time.Parse在解析时间时则反向利用了这种机制。
可以用 nc(netcat)、telnet 连接时钟服务器,也可以用 net.Dial 实现一个简易的 nc。
// nc localhost 8000
// telnet localhost 8000
func main() { // 简易 nc
conn, err := net.Dial("tcp", "localhost:8000") // 只读的 TCP 客户端
if err != nil {
log.Fatal(err)
}
defer conn.Close()
mustCopy(os.Stdout, conn)
}
// 将连接的数据写入到标准输出,直到 EOF 或是出现错误
func mustCopy(dst io.Writer, src io.Reader) {
if _, err := io.Copy(dst, src); err != nil {
log.Fatal(err)
}
}
用 go handleConn(conn) 让每个连接在独立的协程里被处理,就完成了并发时钟服务的改造。
并发回声服务(在同一个连接中也使用了多个协程):
func main() {
listener, err := net.Listen("tcp", "localhost:8000")
if err != nil {
log.Fatal(err)
}
for {
conn, err := listener.Accept()
if err != nil {
log.Print(err)
continue
}
go handleConn(conn)
}
}
func handleConn(c net.Conn) {
input := bufio.NewScanner(c)
for input.Scan() {
// echo(c, input.Text(), 1*time.Second) // 同一个连接中,不同的 echo 参数依次打印
go echo(c, input.Text(), 1*time.Second) // 穿插打印
}
// ignoring potential errors from input.Err()
c.Close()
}
func echo(c net.Conn, shout string, delay time.Duration) { // reverb effect
fmt.Fprintln(c, "\t", strings.ToUpper(shout))
time.Sleep(delay)
fmt.Fprintln(c, "\t", shout)
time.Sleep(delay)
fmt.Fprintln(c, "\t", strings.ToLower(shout))
}
简易 nc2:
func main() {
conn, err := net.Dial("tcp", "localhost:8000")
if err != nil {
log.Fatal(err)
}
defer conn.Close()
go mustCopy(os.Stdout, conn) // 将回声服务的响应输出到标准输出
mustCopy(conn, os.Stdin) // 将标准输入的内容传给回声服务
}
func mustCopy(dst io.Writer, src io.Reader) {
if _, err := io.Copy(dst, src); err != nil {
log.Fatal(err)
}
}
并发素数筛:
// https://go.dev/doc/play/sieve.go
// A concurrent prime sieve
package main
// Send the sequence 2, 3, 4, ... to channel 'ch'.
func Generate(ch chan<- int) {
for i := 2; ; i++ {
ch <- i
}
}
// Copy the values from channel 'in' to channel 'out',
// removing those divisible by 'prime'.
func Filter(in <-chan int, out chan<- int, prime int) {
for {
i := <-in // Receive value from 'in'.
if i%prime != 0 {
out <- i // Send 'i' to 'out'. 等价于又一次的 Generate
// 2, 3, 4, 5, 6, 7, 8, 9, ... prime 2
// 3, 5, 7, 9, ... prime 3
// 5, 7, ... prime 5
}
}
}
// The prime sieve: Daisy-chain Filter processes.
func main() {
ch := make(chan int) // Create a new channel.
go Generate(ch) // Launch Generate goroutine.
for i := 0; i < 10; i++ { // 找 10 个素数
prime := <-ch // 初始值 2 是素数,下一次循环中第一个比 2 大且被 2 取余后不为 0 的数必然是素数,以此类推,每次 <-ch 读到的第一个数就是素数
print(prime, "\n")
ch1 := make(chan int)
go Filter(ch, ch1, prime)
ch = ch1
}
}
// 前一个素数过滤后的结果,交给下一个素数继续过滤
通道
通道是一个协程和另一个协程之间传递值的途径。
通道是某种类型(称为通道的元素类型)的值的传递管道。
- 元素类型是
int的通道类型记成chan int。 - 创建通道:
ch := make(chan int)
通道是对 make 创建出来的数据结构的引用,通道的零值是 nil。
通道作为函数参数传递时,实际上是拷贝了引用,函数调用者和被调用的函数的通道变量都指向同一个数据结构。
两个相同类型的通道可以用 == 比较,若它们是对同一个数据结构的引用,则比较结果为 true。
通道也可以和 nil 比较。
通道有两种主要操作:发送(send)和接收(receive)。
两者的总和称为通信(communication)。
发送语句通过通道将一个协程中的值传递给执行相对应的接收表达式的另一个协程。
接收和发送的操作符都是 <-。
ch <- x // 发送语句;x 的值写入通道 ch
x = <-ch // 接收表达式;值从通道 ch 取出后赋给 x
<-ch // 接收语句,值被丢弃
对 nil 通道的发送和接收操作都会永远阻塞。
通道还支持关闭操作(close(ch)),用于设定“不会再有值发送至此通道”的标志。
对关闭的通道进行发送操作会 panic。
对关闭通道进行接收操作可以取到已发送至该通道的值;通道内的值读完(drain)后再继续进行接收操作,接收操作会立刻得到执行,取到的是通道元素类型的零值。
关闭已经关闭的通道会 panic;关闭 nil 通道会 panic。
make 还可以接收一个整数作为第二个参数,称为通道的容量。
ch = make(chan int) // 无缓冲通道
ch = make(chan int, 0) // 无缓冲通道,容量为 0,非 nil
ch = make(chan int, 3) // 容量为 3 的缓冲通道
向无缓冲通道的发送操作(发送在前)会阻塞执行发送操作的协程,直到另一个协程上执行对同一个无缓冲通道的接收操作,值在两个协程间完成传递,两个协程也解除阻塞。相反的,如果接收操作在前,执行该接收操作的协程也会阻塞,需等到出现对同一个无缓冲通道的发送操作后,阻塞才会解除。这里的值的接收发生在执行发送操作的协程的阻塞解除之前。
Communication over an unbuffered channel causes the sending and receiving goroutines to synchronize. Because of this, unbuffered channels are sometimes called synchronous channels. When a value is sent on an unbuffered channel, the receipt of the value happens before the reawakening of the sending goroutine.
在对并发的讨论中,x 发生在 y 之前不仅仅意味着 x 发生的在时间上比 y 早,而是说我们保证 x 发生的时间早于 y,并且 x 事件的所有作用效果(比如变量的更新)已经完成,y 中可以依赖这些作用效果。x 和 y 并发的意思不是 x 和 y 同时发生,而是不能确定 x 和 y 发生的顺序。
简易 nc3:
func main() {
conn, err := net.Dial("tcp", "localhost:8000")
if err != nil {
log.Fatal(err)
}
done := make(chan struct{})
go func() {
io.Copy(os.Stdout, conn) // ignoring errors
log.Println("done")
done <- struct{}{} // signal the main goroutine
}()
mustCopy(conn, os.Stdin)
conn.Close()
<-done // wait for background goroutine to finish
}
func mustCopy(dst io.Writer, src io.Reader) {
if _, err := io.Copy(dst, src); err != nil {
log.Fatal(err)
}
}
- 当用户完成输入,标准输入流关闭,
mustCopy返回,主协程调用conn.Close同时关闭网络连接的读和写。关闭网络连接写的部分后,会触发服务端的 EOF 条件;关闭网络连接读的部分后,在后台执行io.Copy的协程会报 “read from closed connection” 错误(可能导致conn中的数据不能读完)并返回,io.Copy执行结束,并通过done通道通知主协程。
通过通道传递的消息若不传递任何值、只起同步的作用,这样消息也被称为事件(events),这种情况通常会使用元素类型是 struct{},bool 或 int 的通道。
用通道连接协程可以形成管道(pipeline):
func main() {
naturals := make(chan int)
squares := make(chan int)
go func() { // Counter
for x := 0; ; x++ {
naturals <- x
}
}()
go func() { // Squarer
for {
x, ok := <-naturals
if !ok {
break
}
squares <- x * x
}
close(squares)
}()
for {
fmt.Println(<-squares)
}
}
没有可以直接测试通道是否关闭的方法。
通道的接收操作会返回两个值:接收到的通道元素和一个布尔值(标识接收数据是否成功)。成功接收时布尔值为 true;接收的通道已关闭且通道里的值已接收完毕,布尔值为 false。由于这种用法十分常见,Go 也支持用 range 遍历通道实现同样的效果。
go func() { // Squarer2
for {
x, ok := <-naturals
if !ok {
break // channel was closed and drained
}
squares <- x * x
}
close(squares)
}()
go func() { // Squarer3
for x := range naturals {
squares <- x * x
}
close(squares)
}()
不需要一使用完通道就将其关闭,除非是需要通知接收该通道的协程“数据已发送完毕”的情况。Go 的垃圾回收器若判断通道处于不可及(unreachable)的状态,就会将通道的资源回收,无论通道是否已关闭。
Go 的垃圾回收器会回收未使用的内存,但它不会去释放不在使用中的操作系统资源,如打开的文件和网络连接,这些资源必须显式地去关闭。
当通道用作函数参数时,通常情况这样的通道会专门用作发送或专门用作接收;Go 支持单向通道类型。
chan<- int专门用作发送,<-chan int专门用作接收,误用会报编译错误。
双向通道可以类型转换成单向通道,转换的结果不可逆(单向通道不可以转换成双向通道)。
func counter(out chan<- int) {
for x := 0; x < 100; x++ {
out <- x
}
close(out)
}
func squarer(out chan<- int, in <-chan int) {
for v := range in {
out <- v * v
}
close(out)
}
func printer(in <-chan int) {
for v := range in {
fmt.Println(v)
}
}
func main() {
naturals := make(chan int)
squares := make(chan int)
go counter(naturals) // naturals 的副本发生从 chan int 到 chan<- int 的隐式类型转换,naturals 本身仍是双向的
go squarer(squares, naturals) // naturals 的副本发生从 chan int 到 <-chan int 的隐式类型转换,naturals 本身仍是双向的
printer(squares)
}
缓冲通道有一个元素队列,队列容量在 make 时由第二个参数决定。
发送操作往队尾加入一个元素,读取操作从队首移除一个元素。
若通道已满,发送操作会阻塞,直到读取操作为队列腾出空间;相反,若通道是空的,读取操作会阻塞,直到有值被发送至通道;若通道不空也不满,发送和接收操作都能无阻塞地进行(发送协程和接收的协程解耦)。
cap 返回缓冲通道的容量,len 返回缓冲通道中当前缓冲的元素的数量。
通道和协程调度密切相关,若没有另一个协程去对通道进行接收操作,发送操作所在的协程(可能是主协程)就存在永远阻塞的风险。因此不要在同一个协程里把通道当作队列使用,尽管这样使用的语法简单,可以用切片实现简单队列。
下例中,若使用无缓冲通道,另外 2 个返回请求较慢的协程会将返回值写入再也没有任何协程会来读取的通道,导致永远阻塞,这种情况称为协程泄漏,是一种 bug。泄漏的协程不会被自动回收,因此要确保结束掉(return)不会再用到的协程。
func mirroredQuery() string {
responses := make(chan string, 3)
go func() { responses <- request("asia.gopl.io") }()
go func() { responses <- request("europe.gopl.io") }()
go func() { responses <- request("americas.gopl.io") }()
return <-responses // return the quickest response
}
func request(hostname string) (response string) { /* ... */ }
对于缓冲容量为 1 的通道,写入数据相当于加锁,读出数据相当于解锁。
var counter int = 0
var ch = make(chan int, 1)
func Worker() {
ch <- 1
counter++
<- ch
}
实现原理
channel 用一个环形队列作为缓冲区;环形队列用数组实现。
// https://github.com/golang/go/blob/go1.16.6/src/runtime/chan.go#L32
type hchan struct {
qcount uint // 当前队列中剩余元素个数
dataqsiz uint // 环形队列长度,即可以存放的元素个数;管道容量,make 时指定
buf unsafe.Pointer // 环形队列指针
elemsize uint16 // 每个元素的大小,用于在 buf 中定位元素的位置
closed uint32 // 关闭状态的标识
elemtype *_type // 元素类型
sendx uint // 队列下标,标识元素写入时存放到队列中的位置
recvx uint // 队列下标,标识元素从队列的该位置读出
recvq waitq // 等待读消息的 goroutine 队列
sendq waitq // 等待写消息的 goroutine 队列
// lock protects all fields in hchan, as well as several
// fields in sudogs blocked on this channel.
//
// Do not change another G's status while holding this lock
// (in particular, do not ready a G), as this can deadlock
// with stack shrinking.
lock mutex // 互斥锁,一个通道同时仅允许被一个协程读写
}
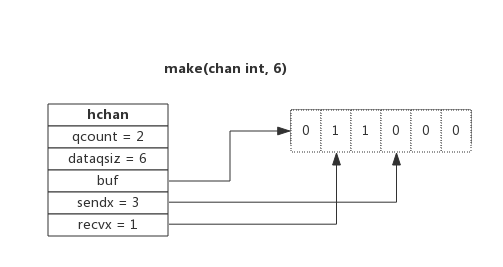
上图为容量为 6 的缓冲通道:
dataqsiz队列长度为 6;buf指向队列所在的内存;qcount表明队列中还有 2 个元素(2 个 1);sendx表示下一个写入数据的存储位置,即队尾,索引为 3(取值范围是 [0,6));recvx表示下一个读取数据的位置,即队首,索引为 1(取值范围是 [0,6))。
读取通道阻塞时,当前协程会被加入 recvq 队列,写入通道阻塞时则会被加入 sendq 队列。因读阻塞的协程会被向通道写入数据的协程唤醒,因写阻塞的协程会被从通道读取数据的协程唤醒。
- 一般情况下
recvq和sendq至少有一个为空,只有一个例外,就是同一个协程使用select边写边读时,该协程在这两个协程中都会出现。 - 当接收队列
recvq不为空时,说明缓冲区没有数据且有协程在等待数据,此时的写数据操作会把数据直接传递给recvq队列中的第一个协程,不必先将数据写入缓冲区。 - 如果等待发送的队列
sendq不为空且缓冲区没有数据,此时的读数据操作将直接从sendq队列中的第一个协程去读。
创建通道实际上就是初始化 hchan 结构体,类型信息(elemtype)和缓冲区长度(dataqsiz)由内置函数 make() 指定,buf 大小由元素大小和缓冲区长度共同决定。
关闭通道时会把 recvq 中的全部协程唤醒,这些协程接收到的数据都为元素类型的零值;同时也会把 sendq 队列中的协程全部唤醒,这些协程会触发 panic。
单向通道只是对通道使用的一种限制,和 C 语言使用 const 修饰函数参数为只读同理,实际上并没有单向通道。
循环的并发处理
当需要循环处理的任务和处理的顺序无关(子任务之间彼此完全独立),是使用并发的好时机,这种问题也称为 embarrassingly parallel。
// 错误示例:makeThumbnails 在执行实际转换工作的协程结束前就返回了
func makeThumbnails(filenames []string) { // 将图片转成缩略图
for _, f := range filenames {
go thumbnail.ImageFile(f) // NOTE: ignoring errors
}
}
不存在直接的方式可以等待一个协程直到它结束,但是内层的协程可以通过向一个内外层协程共享的通道发送事件,向外层协程汇报自己已结束。
func makeThumbnails2(filenames []string) {
ch := make(chan struct{})
for _, f := range filenames {
go func(f string) {
thumbnail.ImageFile(f) // NOTE: ignoring errors
ch <- struct{}{}
}(f) // * 闭包,确保 f 是执行 go 语句当时的文件;不使用闭包很可能会导致所有协程处理的图片都是最后一个图片文件
}
for range filenames {
<-ch
}
}
将工作协程的结果汇总给主协程(存在内存泄漏):
func makeThumbnails3(filenames []string) error {
errors := make(chan error)
for _, f := range filenames {
go func(f string) {
_, err := thumbnail.ImageFile(f)
errors <- err
}(f)
}
for range filenames {
if err := <-errors; err != nil {
return err
}
}
return nil
}
以上写法返回第一个错误后,后续的返回错误的协程都会协程泄漏。解决方法是使用缓冲通道;或者单独创建一个协程来接收(drain)通道的值,makeThumbnails 协程则仍旧在遇到第一个报错时就将错误返回。
func makeThumbnails4(filenames []string) (thumbfiles []string, err error) {
type item struct {
thumbfile string
err error
}
ch := make(chan item, len(filenames)) // 使用缓冲通道
for _, f := range filenames { // 迭代切片
go func(f string) {
var it item
it.thumbfile, it.err = thumbnail.ImageFile(f)
ch <- it
}(f)
}
for range filenames { // 迭代切片
it := <-ch
if it.err != nil {
return nil, it.err
}
thumbfiles = append(thumbfiles, it.thumbfile) // 元素顺序是不确定的
}
return thumbfiles, nil
}
使用并发安全的计数器类型 sync.WaitGroup 是处理事先不确定迭代次数的循环并发的惯用模式:
// 返回所有 thumbnail 图片的总大小
func makeThumbnails5(filenames <-chan string) int64 {
sizes := make(chan int64)
var wg sync.WaitGroup // wg 会在不同协程里被操作
for f := range filenames {
wg.Add(1) // worker 协程加 1
// worker
go func(f string) {
defer wg.Done() // worker 协程减 1
thumb, err := thumbnail.ImageFile(f)
if err != nil {
log.Println(err)
return
}
info, _ := os.Stat(thumb) // OK to ignore error
sizes <- info.Size()
}(f)
}
// closer goroutine
go func() {
wg.Wait() // blocks until the WaitGroup counter is zero
close(sizes)
}()
var total int64
for size := range sizes {
total += size
}
return total
}
Add 的调用必须在 worker 协程启动前,而不是在 worker 协程内部调用,否则不能保证 Add 发生在 Wait 前。wg.Done() 等价于 wg.Add(-1)。
closer 协程里的逻辑必须和对 sizes 进行循环的逻辑并发,若不是并发:
- closer 逻辑在
range sizes前的情况,worker 协程里的sizes <- info.Size()操作一直没有对应的读取操作出现,导致所有 worker 协程都阻塞,计数器不能减小,wg.Wait()也就一直阻塞。 - closer 逻辑在
range sizes后的情况,sizes通道永远无法关闭,导致range sizes循环无法结束,使得 closer 逻辑根本不可及。
并发网页爬虫
利用并发模式改写 函数贴 中的网页爬虫:
func main() {
worklist := make(chan []string)
go func() { worklist <- os.Args[1:] }()
seen := make(map[string]bool)
for list := range worklist { // * worklist 不会被关闭,循环无法结束
for _, link := range list {
if !seen[link] {
seen[link] = true
go func(link string) {
worklist <- crawl(link)
}(link)
}
}
}
}
func crawl(url string) []string {
fmt.Println(url)
list, err := links.Extract(url)
if err != nil {
log.Print(err)
}
return list
}
// ...
// dial tcp 23.21.222.120:443: socket: too many open files
// ...
程序创建的网络连接过多,结果是打开的文件超出每个进程允许的限制,使得 DNS 查询和调用 net.Dial 等操作开始失败。这里的问题出在太“并发”。
可以通过容量为 n 的缓冲通道来实现一种称为计数信号(counting semaphore)的并发原型以限制并发数。
var tokens = make(chan struct{}, 20) // 限制并发数为 20;struct{} 类型的大小为 0
func crawl(url string) []string { // * 在 crawl 逻辑里限制并发数
fmt.Println(url)
tokens <- struct{}{} // 获取令牌
list, err := links.Extract(url)
<-tokens // 释放令牌
if err != nil {
log.Print(err)
}
return list
}
程序还存在的一个问题是它永远不会终止,即使所有链接都已爬完。解决办法如下:
func main() {
worklist := make(chan []string)
var n int // number of pending sends to worklist
n++
go func() { worklist <- os.Args[1:] }() // start with command-line arguments
seen := make(map[string]bool)
for ; n > 0; n-- { // * n 只在 main 协程里被操作,此处与 sync.WaitGroup 不同
list := <-worklist // 通道是个队列,所以仍是广度优先
for _, link := range list {
if !seen[link] {
seen[link] = true
n++
go func(link string) {
worklist <- crawl(link)
}(link)
}
}
}
}
另一种限制并发的方案:
// 未处理程序不能终止的问题
func main() {
worklist := make(chan []string) // lists of URLs, may have duplicates
unseenLinks := make(chan string) // de-duplicated URLs
go func() { worklist <- os.Args[1:] }()
for i := 0; i < 20; i++ { // * 在 main 里限制并发数
go func() {
for link := range unseenLinks { // * 起 20 个线程来 drain(每个协程不是只执行一次 crawl)
foundLinks := crawl(link)
go func() { worklist <- foundLinks }()
}
}()
}
// 主协程将 worklist 里的 url 去重并发送给爬虫协程
seen := make(map[string]bool) // the seen map is confined within the main goroutine
for list := range worklist {
for _, link := range list {
if !seen[link] {
seen[link] = true
unseenLinks <- link
}
}
}
}
func crawl(url string) []string {
fmt.Println(url)
list, err := links.Extract(url)
if err != nil {
log.Print(err)
}
return list
}
select 与多路复用
火箭发射倒计时程序:
func main() {
abort := make(chan struct{})
go func() {
os.Stdin.Read(make([]byte, 1)) // read a single byte
abort <- struct{}{}
}()
fmt.Println("Commencing countdown. Press return to abort.")
tick := time.Tick(1 * time.Second)
for countdown := 10; countdown > 0; countdown-- {
fmt.Println(countdown)
<-tick
// <-abort
}
launch()
}
要实现按下任意键取消发射的功能,每次倒计时需要同时监听两种事件:“滴答”事件和取消事件。但无论哪个接收操作写在前面,都会阻塞另一个,直到写在前面的事件结束。
这种情况需要用到 select 实现多路复用。每个 case 指定一个通信(communication,某个通道上的发送或接收操作)和相应的语句块。
select {
case <-ch1:
// ...
case x := <-ch2:
// ...use x...
case ch3 <- y:
// ...
default:
// ...
}
select 在通信发生前保持阻塞,通信发生时该通信对应的语句块被执行,其它的通信则没有机会再发生。没有 case 的 select 语句 select{} 永远保持阻塞。
func main() {
abort := make(chan struct{})
go func() {
os.Stdin.Read(make([]byte, 1)) // read a single byte
abort <- struct{}{}
}()
fmt.Println("Commencing countdown. Press return to abort.")
select {
case <-time.After(10 * time.Second): // time.After 返回一条通道,并启动一个协程,在指定的时间过后往该通道发送一个值。
// Do nothing.
case <-abort:
fmt.Println("Launch aborted!")
return
}
launch()
}
select 示例:
ch := make(chan int, 1)
for i := 0; i < 10; i++ {
select {
case x := <-ch:
fmt.Println(x) // "0" "2" "4" "6" "8"
case ch <- i:
}
}
若多个 case 都满足,select 会随机选择一个,保证每个通道被选中的概率相等。
支持取消功能,同时打印倒计时:
func main() {
// ...create abort channel...
fmt.Println("Commencing countdown. Press return to abort.")
tick := time.Tick(1 * time.Second)
for countdown := 10; countdown > 0; countdown-- {
fmt.Println(countdown)
select {
case <-tick:
// Do nothing.
case <-abort:
fmt.Println("Launch aborted!")
return
}
}
launch()
}
上面的循环结束后,滴答协程仍会往通道发送数据,但不再有协程会来接收该通道的数据,造成协程泄漏。time.Tick 适用于程序的整个生命周期都需要滴答事件的情况。其它情况更适合用以下模式:
ticker := time.NewTicker(1 * time.Second)
<-ticker.C // receive from the ticker's channel
ticker.Stop() // cause the ticker's goroutine to terminate
select 语句可以有一个 default,指定没有其它通信可以进行时使用的逻辑。
我们若想尝试对通道进行发送或接收操作,还要做到通道没准备好时避免阻塞,就可以用 default 实现非阻塞的通信。
abort := make(chan struct{})
select { // 无阻塞接收操作,反复进行则成为轮询通道
case <-abort:
fmt.Printf("Launch aborted!\n")
return
default:
// do nothing, so control flow moves past select statement and to printing
}
fmt.Println("non-blocking")
// "non-blocking"
创建有时效的通道:
// https://github.com/kubernetes/kubernetes/blob/master/pkg/controller/resourcequota/resource_quota_controller.go#L479
func waitForStopOrTimeout(stopCh <-chan struct{}, timeout time.Duration) <-chan struct{} {
stopChWithTimeout := make(chan struct{})
go func() {
defer close(stopChWithTimeout)
select {
case <-stopCh:
case <-time.After(timeout):
}
}()
return stopChWithTimeout
}
对 nil 通道的发送和接收操作都会永远阻塞,在 select 语句中可以利用 nil 通道来启停某些功能,如处理超时、取消操作。
select 的 case 语句在读取通道时即使通道为空也不会阻塞,因为 case 语句编译后调用读通道时会明确传入不阻塞的参数,读不到数据不会将当前协程加入等待队列 recvq,而是直接返回。
select 原理
// https://github.com/golang/go/blob/go1.16.6/src/runtime/select.go#L19
type scase struct {
c *hchan // 操作的通道
elem unsafe.Pointer // 从通道读出的数据或写入通道的数据的存放地址
}
scase 的成员 c 表示 case 语句操作的通道,每个 scase 仅能存在一个通道,这一点直接决定了每个 case 语句仅能处理一个通道。编译器在处理 case 语句时,如果 case 语句中没有通道操作(即不能处理成 scase 对象),则会报出编译错误(select case must be receive, send or assign recv)。
selectgo 方法用于处理 select 语句,它从一组 case 语句中挑选一个 case,并返回命中 case 的下标;若选中的 case 对应的 scase 是个接收操作,第二个参数返回的是数据是否接收成功。
// https://github.com/golang/go/blob/go1.16.6/src/runtime/select.go#L121
func selectgo(cas0 *scase, order0 *uint16, pc0 *uintptr, nsends, nrecvs int, block bool) (int, bool) {
// NOTE: In order to maintain a lean stack size, the number of scases
// is capped at 65536.
cas1 := (*[1 << 16]scase)(unsafe.Pointer(cas0))
order1 := (*[1 << 17]uint16)(unsafe.Pointer(order0))
ncases := nsends + nrecvs
scases := cas1[:ncases:ncases]
// pollorder 和 lockorder 分别占据源数组的前半部分和后半部分,共享底层数组同时避免了越界
pollorder := order1[:ncases:ncases]
lockorder := order1[ncases:][:ncases:ncases]
// generate permuted order
norder := 0
for i := range scases {
cas := &scases[i]
// Omit cases without channels from the poll and lock orders.
if cas.c == nil {
cas.elem = nil // allow GC
continue
}
j := fastrandn(uint32(norder + 1))
pollorder[norder] = pollorder[j]
pollorder[j] = uint16(i)
norder++
}
pollorder = pollorder[:norder]
lockorder = lockorder[:norder]
}
编译器将 select 中的 case 保存在数组 cas0 中。order0 是一个整形数组地址,长度是 case 个数的 2 倍。ncases 是 case 的个数(包括 default),即 cas0 的长度。
order1 数组被一分为 2,前半部分存放 case 的随机顺序 pollorder,selectgo 会将原始 case 的顺序打乱(fastrandn()),这样一来检查每个 case 是否就绪时就会表现出随机性;后半部分存放通道加锁的顺序 lockorder,selectgo 会按照通道地址顺序对多个通道加锁,避免因重复加锁引发死锁问题。
当所有 case 均未就绪时,selectgo 阻塞,函数不会返回,一旦返回就说明某个 case 已就绪,返回的 case 编号是代码中编写的 case 的顺序(打乱之前)。
目录的并发遍历
汇报目录的磁盘使用情况(类似 Unix 的 du 命令,disk usage):
func main() {
flag.Parse()
roots := flag.Args() // returns the non-flag command-line arguments
if len(roots) == 0 {
roots = []string{"."}
}
fileSizes := make(chan int64)
go func() {
for _, root := range roots {
walkDir(root, fileSizes)
}
close(fileSizes)
}()
var nfiles, nbytes int64
for size := range fileSizes {
nfiles++
nbytes += size
}
printDiskUsage(nfiles, nbytes)
}
func printDiskUsage(nfiles, nbytes int64) {
fmt.Printf("%d files %.1f GB\n", nfiles, float64(nbytes)/1e9)
}
func walkDir(dir string, fileSizes chan<- int64) {
for _, entry := range dirents(dir) {
if entry.IsDir() {
subdir := filepath.Join(dir, entry.Name())
walkDir(subdir, fileSizes)
} else {
fileSizes <- entry.Size()
}
}
}
func dirents(dir string) []os.FileInfo {
entries, err := ioutil.ReadDir(dir) // 返回一个 os.FileInfo 切片
if err != nil {
fmt.Fprintf(os.Stderr, "du: %v\n", err)
return nil
}
return entries
}
周期性打印进度:
var verbose = flag.Bool("v", false, "show verbose progress messages")
func main() {
// ...start background goroutine...
var tick <-chan time.Time
if *verbose {
tick = time.Tick(500 * time.Millisecond)
}
var nfiles, nbytes int64
loop:
for {
select {
case size, ok := <-fileSizes:
if !ok {
break loop // fileSizes 关闭,同时跳出 select 和 for 循环;只用 break 只会跳出 select
}
nfiles++
nbytes += size
case <-tick:
printDiskUsage(nfiles, nbytes)
}
}
printDiskUsage(nfiles, nbytes) // final totals
}
并发执行 walkDir,并限制并发数量:
func main() {
// ...
fileSizes := make(chan int64)
var n sync.WaitGroup
for _, root := range roots {
n.Add(1)
go walkDir(root, &n, fileSizes)
}
go func() {
n.Wait()
close(fileSizes)
}()
// ...select loop...
}
func walkDir(dir string, n *sync.WaitGroup, fileSizes chan<- int64) {
defer n.Done()
for _, entry := range dirents(dir) {
if entry.IsDir() {
n.Add(1)
subdir := filepath.Join(dir, entry.Name())
go walkDir(subdir, n, fileSizes)
} else {
fileSizes <- entry.Size()
}
}
}
var sema = make(chan struct{}, 20)
func dirents(dir string) []os.FileInfo {
sema <- struct{}{}
defer func() { <-sema }()
entries, err := ioutil.ReadDir(dir) // 返回一个 os.FileInfo 切片
if err != nil {
fmt.Fprintf(os.Stderr, "du: %v\n", err)
return nil
}
return entries
}
取消任意多个协程
一个协程不能直接终止另一个协程,因为这样会使被终止协程的(与它的子协程的)共享变量处于未定义的(undefined)状态。
“火箭发射倒计时”示例中通过向 abort 通道发送事件,使得倒计时协程终止。此种方法不适用于取消任意多个协程,因为我们我们无法准确地知道某个时刻有多少个协程在工作:有些协程可能已经结束运行因而终止,有些协程可能创建于其它协程之中。
对于取消操作,需要有一个可靠的机制将一个事件通过通道广播出去,让协程可以知道事件正在发生或是事件已发生过。
通道关闭后,后续对该通道的接收操作会立刻得到执行,并取到通道元素类型的零值,可以利用这一机制实现广播。
支持取消的目录并发遍历:
var done = make(chan struct{})
func main() {
// ...
go func() {
os.Stdin.Read(make([]byte, 1)) // read a single byte
close(done) // 不往通道写数据,而是关闭通道,配合 select 语句
}()
for {
select {
case <-done:
// Drain fileSizes to allow existing goroutines to finish.
for range fileSizes {
// Do nothing.
}
return
case size, ok := <-fileSizes:
// ...
}
}
// ...
}
func cancelled() bool {
select {
case <-done:
return true
default:
return false
}
}
func walkDir(dir string, n *sync.WaitGroup, fileSizes chan<- int64) {
defer n.Done()
if cancelled() { // 取消事件被广播之后的协程直接返回,不进行实质的操作
return
}
for _, entry := range dirents(dir) { // 循环里也加上取消判断可以进一步避免新的协程被创建
// ...
}
}
对取消操作更快的响应需要在程序逻辑里插入更多的侵入式判断逻辑,通常只需要在几处关键处加上取消判断的逻辑即可。
性能分析显示程序的瓶颈在计数信号令牌的获取上,此处加上判断逻辑可使取消的延时从几百毫秒降到几十毫秒。
func dirents(dir string) []os.FileInfo {
select {
case sema <- struct{}{}: // acquire token
case <-done:
return nil // 此时 defer 未被执行,不会因为 <-sema 造成可能的阻塞(https://play.golang.org/p/J98264JT0cm)
}
defer func() { <-sema }() // release token
// ...read directory...
}
调试过程中,取消事件发生后,可以不从 main 函数返回,而是执行 panic 操作,这样运行时就会将程序中每个协程的栈全部打印出来。打印结果若只剩下一个主协程,说明取消操作执行成功;若还有其它协程,则表示它们没有被正确地取消,或者已被取消但是取消操作比较耗时导致尚未结束,打印出的信息通常足以将这两种情况区分。
聊天服务
主协程监听并接收客户端的网络连接,为每个连接创建单独的 handleConn 协程:
func main() {
listener, err := net.Listen("tcp", "localhost:8000")
if err != nil {
log.Fatal(err)
}
go broadcaster()
for {
conn, err := listener.Accept()
if err != nil {
log.Print(err)
continue
}
go handleConn(conn)
}
}
广播模块:
type client chan<- string // 发送消息的通道
var (
entering = make(chan client)
leaving = make(chan client)
messages = make(chan string) // 所有客户端发送进来的消息
)
func broadcaster() {
// 所有连接的客户端;同类型通道可比较,可用作 map 的键
clients := make(map[client]bool)
for {
select {
case msg := <-messages:
// 将发送进来的消息广播给每个发送消息的通道
for cli := range clients {
cli <- msg
}
case cli := <-entering:
clients[cli] = true
case cli := <-leaving:
delete(clients, cli)
close(cli)
}
}
}
处理客户端连接的模块:
func handleConn(conn net.Conn) {
ch := make(chan string) // outgoing client messages
go clientWriter(conn, ch)
who := conn.RemoteAddr().String()
ch <- "You are " + who
messages <- who + " has arrived"
entering <- ch // 进入的通知在上一条之后,所以自己不会收到“自己加入”的消息
input := bufio.NewScanner(conn)
for input.Scan() {
messages <- who + ": " + input.Text()
}
// NOTE: ignoring potential errors from input.Err()
leaving <- ch
messages <- who + " has left"
conn.Close()
}
func clientWriter(conn net.Conn, ch <-chan string) {
for msg := range ch {
fmt.Fprintln(conn, msg) // NOTE: ignoring network errors
}
}
clients map 限定在广播协程中,不会被并发地访问。多个协程共享的变量只有通道和 net.Conn 的实例,它们都是并发安全的。
References

